خوشهبندی دادهها رو بر اساس شباهتی که دارن، به طوری که دادههای هر خوشه دارای بیشترین شباهت به هم و کمترین شباهت به دادههای خوشههای دیگه هستن، در یک خوشه قرار میده. الگوریتم K-Means یکی از الگوریتمهای مورد استفاده در داده کاوی و یادگیری ماشینی هست که برای خوشهبندی(Clustering) یا دستهبندی بدون نظارت از اون استفاده میشه. در ادامه نحوه کار این الگوریتم رو با یک مثال و پیادهسازی اون به کمک زبان جاوا توضیح میدم.
برای مشخص کردن شباهت دادهها از معیار و راههای مختلفی استفاده میشه که یکی از اونا فاصله اقلیدسی هست و در اینجا هم ما از اون استفاده میکنیم.
اساس کار این الگوریتم به این صورت هست که اول باید تعداد خوشههایی که مد نظر داریم رو مشخص کنیم. بعد از اون الگوریتم از مجموعه داده موجود، به تعداد خوشههایی که مشخص کردیم میاد و به صورت تصادفی تعدادی رو به عنوان مرکز هر خوشه انتخاب میکنه. در مراحل بعدی به این خوشهها دادههای دیگری رو اضافه میکنه و میانگین دادههای هر خوشه رو به عنوان مرکز اون خوشه در نظر میگیره. بعد از انتخاب مراکز خوشه جدید، دادههای موجود در خوشهها دوباره مشخص میشن. دلیلش هم این هست که در هر خوشه با انتخاب مرکز خوشه جدید ممکنه که بعضی از دادههای اون خوشه از اون به بعد به خوشه(های) دیگهای تعلق پیدا کنن.
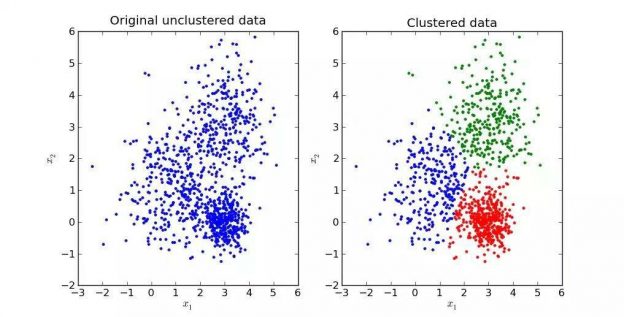
در شکل زیر نمونهای از خوشهبندی نشون داده شده که در اون دادهها به سه خوشه تقسیم و به کمک سه رنگ نمایش داده شدن.
برای درک بهتر نحوه کار الگوریتم K-Means از مثال زیر استفاده میکنم:
فرض میکنیم که مجموعه دادهای داریم که شامل هر ۷ رکورد هست و همه رکوردهای اون ۲ ویژگی یا خصوصیت A و B رو دارن. (دز اینجا میتونیم این ویژگیها رو به عنوان طول و عرض در یک صفحه دو بعدی در نظر بگیریم)
| A | B | |
|---|---|---|
| ۱ | ۱.۰ | ۱.۰ |
| ۲ | ۱.۵ | ۲.۰ |
| ۳ | ۳.۰ | ۴.۰ |
| ۴ | ۵.۰ | ۷.۰ |
| ۵ | ۳.۵ | ۵.۰ |
| ۶ | ۴.۵ | ۵.۰ |
| ۷ | ۳.۵ | ۴.۵ |
فرض میکنیم که قراره دادهها به ۲ خوشه تقسیم بشن. پس برای این منظور به صورت تصادفی ۲ رکورد رو به عنوان مرکز این ۲ خوشه در نظر میگیریم.
| رکورد | مختصات | |
|---|---|---|
| خوشه ۱ | ۱ | (۱.۰ و ۱.۰) |
| خوشه ۲ | ۴ | (۷.۰ و ۵.۰) |
در ادامه الگوریتم دادهها رو به خوشهای که فاصله اقلیدسی کمتری تا مرکز اون داره اختصاص میده. و هربار که داده جدیدی رو به یک خوشه اضافه میکنه مرکز اون خوشه رو هم دوباره محاسبه و مشخص میکنه.
| خوشه ۱ | خوشه ۲ | |||
|---|---|---|---|---|
| گام | رکورد | مرکز خوشه | رکورد | مرکز خوشه |
| ۱ | ۱ | (۱.۰ و ۱.۰) | ۴ | (۷.۰ و ۵.۰) |
| ۲ | ۱ و ۲ | (۱.۵ و ۱.۲) | ۴ | (۷.۰ و ۵.۰) |
| ۳ | ۱ و ۲ و ۳ | (۲.۳ و ۱.۸) | ۴ | (۷.۰ و ۵.۰) |
| ۴ | ۱ و ۲ و ۳ | (۲.۳ و ۱.۸) | ۴ و ۵ | (۶.۰ و ۴.۲) |
| ۵ | ۱ و ۲ و ۳ | (۲.۳ و ۱.۸) | ۴ و ۵ و ۶ | (۵.۷ و ۴.۳) |
| ۶ | ۱ و ۲ و ۳ | (۲.۳ و ۱.۸) | ۴ و ۵ و ۶ و ۷ | (۵.۴ و ۴.۱) |
پس در ادامه مرکزهای خوشهها به صورت زیر در میان.
| رکورد | مرکز خوشه | |
|---|---|---|
| خوشه ۱ | ۱ و ۲ و ۳ | (۲.۳ و ۱.۸) |
| خوشه ۲ | ۴ و ۵ و ۶ و ۷ | (۵.۴ و ۴.۱) |
در ادامه فاصله دادهها تا این مرکزهای خوشههای جدید به شکل جدول زیر در میان.
| رکورد | فاصله تا خوشه ۱ | فاصله تا خوشه ۲ |
|---|---|---|
| ۱ | ۱.۵ | ۵.۴ |
| ۲ | ۰.۴ | ۴.۳ |
| ۳ | ۲.۱ | ۱.۸ |
| ۴ | ۵.۷ | ۱.۸ |
| ۵ | ۳.۲ | ۰.۷ |
| ۶ | ۳.۸ | ۰.۶ |
| ۷ | ۲.۸ | ۱.۱ |
در نتیجه و بر اساس این مراحل و اطلاعات مشاهده میکنیم رکورد ۳ که مربوط به خوشه ۱ بوده، فاصلش تا مرکز خوشه ۲ کمتر میشه. پس این رکورد رو باید به خوشه ۲ اختصاص بدیم.
| رکورد | مرکز خوشه | |
|---|---|---|
| خوشه ۱ | ۱ و ۲ | خوشه ۱ |
| خوشه ۲ | ۳ و ۴ و ۵ و ۶ و ۷ | خوشه ۲ |
و کل این فرایند و مراحل تا زمانی انجام میشه که تغییر و جابجایی در خوشهها اتفاق نیفته.
این الگوریتم رو به راحتی و به کمک زبانهای برنامهنویسی مختلفی میشه پیادهسازی کرد و در ادامه من پیادهسازی این الگوریتم رو برای همین مثال و به زبان جاوا و پایتون در اینجا شرح میدم.
پیادهسازی الگوریتم K-Means به زبان Java
import java.util.ArrayList;
public class KMeans_Ex {
private static final int NUM_CLUSTERS = 2; // Total clusters.
private static final int TOTAL_DATA = 7; // Total data points.
private static final double SAMPLES[][] = new double[][]{{1.0, 1.0},
{1.5, 2.0},
{3.0, 4.0},
{5.0, 7.0},
{3.5, 5.0},
{4.5, 5.0},
{3.5, 4.5}};
private static ArrayList<Data> dataSet = new ArrayList<Data>();
private static ArrayList<Centroid> centroids = new ArrayList<Centroid>();
private static void initialize() {
System.out.println("Centroids initialized at:");
centroids.add(new Centroid(1.0, 1.0)); // lowest set.
centroids.add(new Centroid(5.0, 7.0)); // highest set.
System.out.println(" (" + centroids.get(0).X() + ", " + centroids.get(0).Y() + ")");
System.out.println(" (" + centroids.get(1).X() + ", " + centroids.get(1).Y() + ")");
System.out.print("\n");
return;
}
private static void kMeanCluster() {
final double bigNumber = Math.pow(10, 10); // some big number that's sure to be larger than our data range.
double minimum = bigNumber; // The minimum value to beat.
double distance = 0.0; // The current minimum value.
int sampleNumber = 0;
int cluster = 0;
boolean isStillMoving = true;
Data newData = null;
// Add in new data, one at a time, recalculating centroids with each new one.
while (dataSet.size() < TOTAL_DATA) {
newData = new Data(SAMPLES[sampleNumber][0], SAMPLES[sampleNumber][1]);
dataSet.add(newData);
minimum = bigNumber;
for (int i = 0; i < NUM_CLUSTERS; i++) {
distance = dist(newData, centroids.get(i));
if (distance < minimum) {
minimum = distance;
cluster = i;
}
}
newData.cluster(cluster);
// calculate new centroids.
for (int i = 0; i < NUM_CLUSTERS; i++) {
int totalX = 0;
int totalY = 0;
int totalInCluster = 0;
for (int j = 0; j < dataSet.size(); j++) {
if (dataSet.get(j).cluster() == i) {
totalX += dataSet.get(j).X();
totalY += dataSet.get(j).Y();
totalInCluster++;
}
}
if (totalInCluster > 0) {
centroids.get(i).X(totalX / totalInCluster);
centroids.get(i).Y(totalY / totalInCluster);
}
}
sampleNumber++;
}
// Now, keep shifting centroids until equilibrium occurs.
while (isStillMoving) {
// calculate new centroids.
for (int i = 0; i < NUM_CLUSTERS; i++) {
int totalX = 0;
int totalY = 0;
int totalInCluster = 0;
for (int j = 0; j < dataSet.size(); j++) {
if (dataSet.get(j).cluster() == i) {
totalX += dataSet.get(j).X();
totalY += dataSet.get(j).Y();
totalInCluster++;
}
}
if (totalInCluster > 0) {
centroids.get(i).X(totalX / totalInCluster);
centroids.get(i).Y(totalY / totalInCluster);
}
}
// Assign all data to the new centroids
isStillMoving = false;
for (int i = 0; i < dataSet.size(); i++) {
Data tempData = dataSet.get(i);
minimum = bigNumber;
for (int j = 0; j < NUM_CLUSTERS; j++) {
distance = dist(tempData, centroids.get(j));
if (distance < minimum) {
minimum = distance;
cluster = j;
}
}
tempData.cluster(cluster);
if (tempData.cluster() != cluster) {
tempData.cluster(cluster);
isStillMoving = true;
}
}
}
return;
}
/**
* // Calculate Euclidean distance.
*
* @param d - Data object.
* @param c - Centroid object.
* @return - double value.
*/
private static double dist(Data d, Centroid c) {
return Math.sqrt(Math.pow((c.Y() - d.Y()), 2) + Math.pow((c.X() - d.X()), 2));
}
private static class Data {
private double mX = 0;
private double mY = 0;
private int mCluster = 0;
public Data() {
return;
}
public Data(double x, double y) {
this.X(x);
this.Y(y);
return;
}
public void X(double x) {
this.mX = x;
return;
}
public double X() {
return this.mX;
}
public void Y(double y) {
this.mY = y;
return;
}
public double Y() {
return this.mY;
}
public void cluster(int clusterNumber) {
this.mCluster = clusterNumber;
return;
}
public int cluster() {
return this.mCluster;
}
}
private static class Centroid {
private double mX = 0.0;
private double mY = 0.0;
public Centroid() {
return;
}
public Centroid(double newX, double newY) {
this.mX = newX;
this.mY = newY;
return;
}
public void X(double newX) {
this.mX = newX;
return;
}
public double X() {
return this.mX;
}
public void Y(double newY) {
this.mY = newY;
return;
}
public double Y() {
return this.mY;
}
}
public static void main(String[] args) {
initialize();
kMeanCluster();
// Print out clustering results.
for (int i = 0; i < NUM_CLUSTERS; i++) {
System.out.println("Cluster " + i + " includes:");
for (int j = 0; j < TOTAL_DATA; j++) {
if (dataSet.get(j).cluster() == i) {
System.out.println(" (" + dataSet.get(j).X() + ", " + dataSet.get(j).Y() + ")");
}
} // j
System.out.println();
} // i
// Print out centroid results.
System.out.println("Centroids finalized at:");
for (int i = 0; i < NUM_CLUSTERS; i++) {
System.out.println(" (" + centroids.get(i).X() + ", " + centroids.get(i).Y() + ")");
}
System.out.print("\n");
return;
}
پیادهسازی الگوریتم K-Means به زبانPython
import math
NUM_CLUSTERS = 2
TOTAL_DATA = 7
LOWEST_SAMPLE_POINT = 0 # element 0 of SAMPLES.
HIGHEST_SAMPLE_POINT = 3 # element 3 of SAMPLES.
BIG_NUMBER = math.pow(10, 10)
SAMPLES = [[1.0, 1.0], [1.5, 2.0], [3.0, 4.0], [5.0, 7.0], [3.5, 5.0], [4.5, 5.0], [3.5, 4.5]]
data = []
centroids = []
class DataPoint:
def __init__(self, x, y):
self.x = x
self.y = y
def set_x(self, x):
self.x = x
def get_x(self):
return self.x
def set_y(self, y):
self.y = y
def get_y(self):
return self.y
def set_cluster(self, clusterNumber):
self.clusterNumber = clusterNumber
def get_cluster(self):
return self.clusterNumber
class Centroid:
def __init__(self, x, y):
self.x = x
self.y = y
def set_x(self, x):
self.x = x
def get_x(self):
return self.x
def set_y(self, y):
self.y = y
def get_y(self):
return self.y
def initialize_centroids():
# Set the centoid coordinates to match the data points furthest from each other.
# In this example, (1.0, 1.0) and (5.0, 7.0)
centroids.append(Centroid(SAMPLES[LOWEST_SAMPLE_POINT][0], SAMPLES[LOWEST_SAMPLE_POINT][1]))
centroids.append(Centroid(SAMPLES[HIGHEST_SAMPLE_POINT][0], SAMPLES[HIGHEST_SAMPLE_POINT][1]))
print("Centroids initialized at:")
print("(", centroids[0].get_x(), ", ", centroids[0].get_y(), ")")
print("(", centroids[1].get_x(), ", ", centroids[1].get_y(), ")")
print()
return
def initialize_datapoints():
# DataPoint objects' x and y values are taken from the SAMPLE array.
# The DataPoints associated with LOWEST_SAMPLE_POINT and HIGHEST_SAMPLE_POINT are initially
# assigned to the clusters matching the LOWEST_SAMPLE_POINT and HIGHEST_SAMPLE_POINT centroids.
for i in range(TOTAL_DATA):
newPoint = DataPoint(SAMPLES[i][0], SAMPLES[i][1])
if (i == LOWEST_SAMPLE_POINT):
newPoint.set_cluster(0)
elif (i == HIGHEST_SAMPLE_POINT):
newPoint.set_cluster(1)
else:
newPoint.set_cluster(None)
data.append(newPoint)
return
def get_distance(dataPointX, dataPointY, centroidX, centroidY):
# Calculate Euclidean distance.
return math.sqrt(math.pow((centroidY - dataPointY), 2) + math.pow((centroidX - dataPointX), 2))
def recalculate_centroids():
totalX = 0
totalY = 0
totalInCluster = 0
for j in range(NUM_CLUSTERS):
for k in range(len(data)):
if (data[k].get_cluster() == j):
totalX += data[k].get_x()
totalY += data[k].get_y()
totalInCluster += 1
if (totalInCluster > 0):
centroids[j].set_x(totalX / totalInCluster)
centroids[j].set_y(totalY / totalInCluster)
return
def update_clusters():
isStillMoving = 0
for i in range(TOTAL_DATA):
bestMinimum = BIG_NUMBER
currentCluster = 0
for j in range(NUM_CLUSTERS):
distance = get_distance(data[i].get_x(), data[i].get_y(), centroids[j].get_x(), centroids[j].get_y())
if (distance < bestMinimum):
bestMinimum = distance
currentCluster = j
data[i].set_cluster(currentCluster)
if (data[i].get_cluster() is None or data[i].get_cluster() != currentCluster):
data[i].set_cluster(currentCluster)
isStillMoving = 1
return isStillMoving
def perform_kmeans():
isStillMoving = 1
initialize_centroids()
initialize_datapoints()
while (isStillMoving):
recalculate_centroids()
isStillMoving = update_clusters()
return
def print_results():
for i in range(NUM_CLUSTERS):
print("Cluster ", i, " includes:")
for j in range(TOTAL_DATA):
if (data[j].get_cluster() == i):
print("(", data[j].get_x(), ", ", data[j].get_y(), ")")
print()
return
perform_kmeans()
print_results()
در این الگوریتم وقتی مرکز خوشه محاسبه میشه خیلی پیش میاد که این مرکز خوشه محاسبهشده در بین دادههای واقعی موجود نباشه و صرفا یه میانگین محسوب میشه که همین موضوع باعث مقاوم نبودن این الگوریتم در برابر دادههای پرت مبشه. برای حل این مشکل الگوریتمی پیشنهاد شده به نام K-Medoids که در این الگوریتم مرکز خوشه جدید وقتی محاسبه میشه خودش هم در بین دادههای اصلی موجود هست. با کمی تغییر در الگوریتم K-Means میتونیم K-Medoids رو هم داشته باشیم.
این برنامه در سایت گیتلب قابل دسترس هست و شما میتونید اون رو تغییر بدین و بهترش کنید. اگر هم وقتش رو دارید میتونید الگوریتم K-Medoids رو به این پروژه اضافه کنید و درخواست مرج بدید، خوشحال میشم که پذیرش کنم.
پیادهسازی الگوریتم KMEANS به زبان JAVA در گیتلب
پیادهسازی الگوریتم KMEANS به زبان PYTHON در گیتلب
شاد باشید.
خیلی ممنون از قرار دادن نحوه ی پیاده سازی در جاوا
قربانت دوست عزیز. امیدوارم به کارت اومده باشه.
سلام
میشه فایل پایتون پیاده سازی kmean رو برام بفرستید خیلی احتیاج دارم
وقتی کد رو داخل پایتون کپی می کنم به if ها گیر میده
ممنونم
سلام. بله مشکلی نیست. البته من باز تست کردم و مشکلی هم نداشت.
با عرض سلام و خدا قوت
داداش عزیزم یه عمر دعات میکنم اگه بدانی چقدر گیرم اگه میتونی فایل پایتون k-means , k-medoids برام ایمیل کنی
خیلی خیلی ممنونت میشم.اگه k-medoids نداری عیبی نداره بدشانسی من دمت گرم
با عرض سلام و سپاس.
همون کدها رو شما میتونید کپی کنید و استفاده کنید. بیش از این رو زمان به من اجازه نمیده.
موفق باشید.
سلام . خیلی ممنون از آموزش خوبتون..
فقط یه سوال.. اینکه گاهی اوقات برای الگوریتم k-mean میان Seed انتخاب میکنن واسه چیه؟ بطور کلی Seed چیکار میکنه و چه عددی برای اون مناسبه؟
ممنون میشم اگر توضیح بدین..
با تشکر
سلام. خوشحالم از که مفید بوده چیزی که نوشتم.
در هربار اجرای الگوریتم k-means تضمینی نیست که جوابها یکسان باشن. برای همین با این پارامتر seed میان کاری میکنن که تولید ورودیهای تصادفی هربار یکسان باشه که نتایج هربار یکسان و به اصطلاح consistent باشن و در نتیجه بشه تغییراتی که در الگوریتم میدیم رو بهتر متوجه بشیم.
این لینک هم شاید کمک کنه به درک بهتر: https://en.wikipedia.org/wiki/Random_seed#:~:text=A%20random%20seed%20(or%20seed,initialize%20a%20pseudorandom%20number%20generator.&text=Random%20seeds%20are%20often%20generated,a%20hardware%20random%20number%20generator.
موفق باشید.