
امروز قصد دارم قبل از وارد شدن به مباحث ریاضی، به صورت کلی راجع به SVMها صحبت کنم و مروری روی آنها داشته باشم.
SVM دقیقا چه چیزی هست؟
SVM یک مدل یادگیری نظارت شده است.
پس قبل از این که به سراغ آن برویم باید یک مجموعه داده(Dataset) که از قبل برچسبگذاری شده(Labeled) را داشته باشیم.
مثال: فرض کنیم من صاحب یک کسبوکار هستم و هر روز تعداد زیادی ایمیل از مشتریها دریافت میکنم. بعضی از این ایمیلها شکایتها و نارضایتیهایی هستند که من هرچه سریعتر باید به آنها پاسخ بدهم و به آنها رسیدگی کنم. در غیر این صورت کسبوکار من با ضرر روبرو خواهد شد.
من به دنبال راهی هستم که این ایمیلها را هرچه سریعتر تشخیص بدهم(پیدا کنم) و پاسخ آنها را زودتر از بقیه ارسال کنم.
رویکرد اول: من میتوانم برچسبهایی با عنوانهای: اورژانسی، شکایت و راهنمایی در جیمیل(GMail) خود ایجاد کنم.
اشکال این روش این است که من باید مدتی فکر کنم و همه کلمههای کلیدی(Keyword) بالغوه که مشتریهای عصبانی ممکن است در ایمیلهای خود استفاده کنند را پیدا کنم. طبیعی است که بعضی از آنها را هم از قلم انداخته شوند. با گذشت زمان هم لیست این کلمهها به احتمال زیاد شلوغ و مدیریت کردن آنها به کار مشکلی تبدیل میشود.
رویکرد دوم: من میتوانم از یک الگوریتم یادگیری ماشین نظارت شده استفاده کنم.
قدم اول: به تعدادی ایمیل نیاز دارم.(هرچه بیشتر بهتر)
قدم دوم: عنوان ایمیلهای قدم اول رو میخوانم و آنها را در یکی از دو گروه «شکایت است» و یا «شکایت نیست» طبقهبندی میکنم. اینجوری میتوانم ایمیلها را برچسب گذاری کنم.
قدم سوم: روی این مجموعه داده، مدلی را آموزش میدهم.
قدم چهارم: کیفیت یا صحت پیشبینی های مدل آموزش دادهشده را ارزیابی میکنم.(با استفاده از روش Cross Validation)
قدم پنجم: از این مدل برای پیشبینی این که ایمیلهای جدیدی که رسیدهاند، شکایت هستند یا نه، استفاده میکنم.
در این رویکرد اگر مدل را با تعداد ایمیلهای زیادی آموزش داده باشیم، مدل عملکرد خوبی را نشون میدهد. SVM فقط یکی از روشهایی هست که ما میتوانیم برای یادگرفتن از دادههای موجود و پیشبینی کردن، استفاده کنیم.
همچنین باید به این نکته هم توجه داشته باشیم که قدم دوم اهمیت زیادی دارد و دلیلش این است که اگر در شروع کار، ایمیلهای برچسبگذاری نشده را به SVM بدهیم، کار خاصی را نمیتواند انجام دهد.
SVM یک مدل خطی را یاد میگیرد
در مثال قبل دیدیم که در قدم سوم یک الگوریتم یادگیری نظارت شده مثل SVM به کمک دادههایی که از قبل برچسبگذاری شدهاند آموزش داده شد. اما برای چه چیزی آموزش داده شد؟ برای این که چیزی را یاد بگیرد.
چه چیزی را یاد بگیرد؟
در مورد SVM، یک مدل خطی را یاد میگیرد.
مدل خطی چیست؟ اگر بخواهیم به زبان ساده بیان کنیم یک خط است.(و در حالت پیچیدهتر یک ابر صفحه).
اگر دادههای شما خیلی ساده و دو بعدی باشند، در این صورت SVM خطی را یاد میگیرد که آن خط میتواند دادهها را به دو بخش تقسیم کند.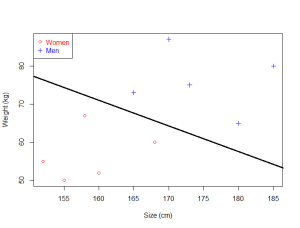
SVM قادر است که خطی را پیدا کند که دادهها را جدا میکند.
خب پس اگر SVM فقط یک خط است، پس چرا ما داریم راجع به مدل خطی صحبت میکنیم؟
برای این که ما همینطوری نمیتوانیم به یک خط چیزی را آموزش بدهیم.
در عوض:
- در نظر میگیریم که دادههایی که میخواهیم طبقهبندی کنیم، میتوانند به وسیله یک خط از هم تفکیک شوند.
- میدانیم که یک خط میتواند به کمک معادله y=wx+by=wx+b نمایش داده شود.(این همان مدل ما است)
- میدانیم با تغییر دادن مقدار w و b بینهایت خط وجود خواهد داشت.
- برای تعیین این که کدام مقدار w و b بهترینخط جداکننده دادهها را به ما میدهد، از یک الگوریتم استفاده میکنیم.
SVM یکی از این الگوریتمها هست که میتواند این کار را انجام دهد.
الگوریتم یا مدل؟
در شروع این پست من نوشتم که SVM یک مدل یادگیری نظارت شده است، و الآن مینویسم که آن یک الگوریتم است. چه شده؟ از واژه الگوریتم معمولا آزادانه استفاده میشود. برای نمونه، ممکن است که شما جایی بخوانید یا بشنوید که SVM یک الگوریتم یادگیری نظارت شده است. اگر این نکته را در نظر بگیریم که الگوریتم مجموعهای از فعالیتها است که انجام میشوند تا به نتیجه مشخصی دست یابیم، میبینیم که استفاده از این واژه در اینجا صحیح نیست(منظور از واژه الگوریتم اینجا الگوریتمی است که برای آموزش از آن استفاده میکنیم). بهینهسازی متوالی کمینه(Sequential minimal optimization) پر استفاده ترین الگوریتم برای آموزش SVM است. با این حال میتوان از الگوریتمهای دیگری مثل کاهش مختصات(Coordinate descent) هم استفاده کرد. در کل بیشتر به جزییاتی مثل این علاقمند نیستند، در نتیجه ما هم برای سادهتر شدن فقط از واژه الگوریتم SVM استفاده میکنیم(بدون ذکر جزییات الگوریتم آموزشی که استفاده میکنیم).
SVM یا SVMها؟
بعضی وقتها میبینیم که مردم راجع به SVM و بعضی وقتها هم راجع به SVMها صحبت میکنند.
طبق معمول ویکیپدیا در روشن و شفاف کردن چیزها به ما کمک میکند:
در یادگیری ماشینی، ماشینهای بردار پشتیبان (SVMs) مدلهای یادگیری نظارت شده به همراه الگوریتمهای آموزش مربوطه هستند که در تحلیل دادههای استفاده شده در رگرسیون و طبقهبندی از آنها استفاده میشود.(ویکیپدیا)
پس حالا ما این را میدانیم که چندین مدل متعلق به خانواده SVM وجود دارند.
SVMها – ماشینهای بردار پشتیبان
بر اساس ویکیپدیا SVMها همچنین میتوانند برای دو چیز استفاده شوند، طبقهبندی و رگرسیون.
- SVM برای طبقهبندی استفاده میشود.
- SVR یا(Support Vector Regression) برای رگرسیون.
پس گفتن ماشینهای بردار پشتیبان هم دیگه الآن منطقی به نظر میاد. با این وجود این پایان داستان نیست!
طبقهبندی
در سال ۱۹۵۷ یک مدل خطی ساده به نام پرسپترون توسط فردی به نام فرانک روزنبلت برای طبقهبندی اختراع شد(که در واقع اساس شبکههای عصبی سادهای به نام پرسپترون چند لایه است).
چند سال بعد، واپنیک و چروننکیس مدل دیگری به نام «طبقهبندی کننده حداکث حاشیه» پیشنهاد دادند و همانجا بود که SVM متولد شد.
در سال ۱۹۹۲ واپنیک و همکارانش ایدهای داشتند که یک چیزی به نام کلک کرنل(Kernel Trick) را به روش قبلی اضافه کنند تا به آنها اجازه دهد که حتی دادههایی که به صورت خطی تفکیکپذیر نیستند را هم طبقهبندی کنند.
سرانجام در سال ۱۹۹۵، کورتز و واپنیک، طبقهبندی کننده حاشیه نرم را معرفی کردند که به SVM اجازه میدهد تا بعضی از اشتباهات در طبقهبندی را هم بپذیرد.
پس وقتی که ما از طبقهبندی صحبت میکنیم، چهار ماشین بردار پشتیبان مختلف وجود دارد.
- طبقهبندی کننده حاشیه حداکثر.
- نسخهای که از کلک کرنل استفاده میکند.
- نسخهای که از حاشیه نرم استفاده میکند.
- نسخهای که ترکیب همه موارد قبلی است.
و البته آخرین روش معمولا بیشترین کاربرد را دارد. دلیل اصلی این که قهمیدن SVMها در نگاه اول کمی گیج کننده به نظر میرسد هم همین موضو ع است که آنها از چندین قطعه تسکیل شده اند که در طول زمان به آنها چیزهایی اضافه شده است.
به همین دلیل است که وقتی از یک زبان برنامهنویسی استفاده میکنید میپرسید از کدام کرنل باید استفاده کنیم(بخاطر کرنلهای مختلفی که وجود دارند) و یا کدام مقدار ابرپارامتر C را باید استفاده کنید(برای کنترل تاثیر حاشیه نرم).
رگرسیون
در سال ۱۹۹۶، واپنیک و همکارانش، نسخهای از SVM را پیشنهاد دادند که به جای طبقهبندی، عمل رگرسیون را انجام میدهد. این مورد به Support Vector Regression یا SVR معروف است. همانند SVM در این مدل نیز از کلک کرنل و ابرپارامتر C استفاده میشود.
در آینده مقاله سادهای در مورد توضیح چگونگی استفاده از SVR در زبان R خواهم نوشت و آدرس آن را همینجا قرار خواهم داد.
اگر علاقمند هستید که راجع به SVR بیشتر بدانیند، میتوانید به این آموزش خوب که نوشته Smola and Schölkopft است، مراجعه کنید.
خلاصه تاریخچه
- طبقهبندی کننده حاشیه حداکثر (۱۹۶۳ یا ۱۹۷۹)
- کلک کرنل (۱۹۹۲)
- طبقهبندی کننده حاشیه نرم (۱۹۹۵)
- رگرسیون بردار پشتیبان (۱۹۹۶)
در صورتی که مایلید بیشتر راجع به تاریخچه بدانید، میتوانید به مقاله مرور همراه با جزییات از تاریخچه مراجعه کنید.
انواع دیگری از ماشینهای بردار پشتیبان
به دلیل این که SVMها در طبقهبندی خیلی موفق بودند، مردم شروع به فکر کردن راجع به این موضوع کردند که چطور میتوانند از همین منطق در انواع دیگر مسائل استفاده کنند یا این که چطور مشتقات آن را ایجاد کنند. در نتیجه چندین روش مختلف و جالب در خانواده SVM به وجود آمد.
- ماشین بردار پشتیبان ساختیافتهکه توانایی پیشبینی اشیای ساختیافته را دارد.
- ماشین بردار پشتیبان حداقل مربعکه در طبقهبندی و رگرسیون استفاده میشود.
- خوشهبندی بردار پشتیبانکه در تحلیل خوشه استفاده میشود.
- ماشین بردار پشتیبان هدایتیکه در یادگیری نیمه نظارتشده استفاده میشود.
- SVM رتبهبندیبرای مرتب کردن نتایج.
- ماشین بردار پشتیبان تک کلاسهکه برای تشخیص ناهنجاری استفاده میشود.
نتیجهگیری
دیدیم که سختی در درک کردن این که SVMها دقیقا چه چیزی هستند، امری طبیعی است. علتش هم این است که چندین SVM برای چندین منظور وجود دارند. مثل همیشه تاریخ به ما اجازه میدهد که دید بهتری راجع به چگونگی به وجود آمدن SVMهایی که امروزه وجود دارند، داشته باشیم.
امیدوارم این مقاله دید وسیعتری از چشمانداز SVM به شما داده باشد و کمک کرده باشد که بهتر این ماشینها را بشناسید و درک کنید.
اگه مایلید که بیشتر راجع به نحوه کار SVM در طبقهبندی بدانید، میتوانید به آموزشهای ریاضی مربوط به آن مراجعه کنید.
آموزشهای ریاضی
درک مجموعه مفاهیم ریاضی مورد نیاز: