خوشهبندی دادهها رو بر اساس شباهتی که دارن، به طوری که دادههای هر خوشه دارای بیشترین شباهت به هم و کمترین شباهت به دادههای خوشههای دیگه هستن، در یک خوشه قرار میده. الگوریتم K-Means یکی از الگوریتمهای مورد استفاده در داده کاوی و یادگیری ماشینی هست که برای خوشهبندی(Clustering) یا دستهبندی بدون نظارت از اون استفاده میشه. در ادامه نحوه کار این الگوریتم رو با یک مثال و پیادهسازی اون به کمک زبان جاوا توضیح میدم.
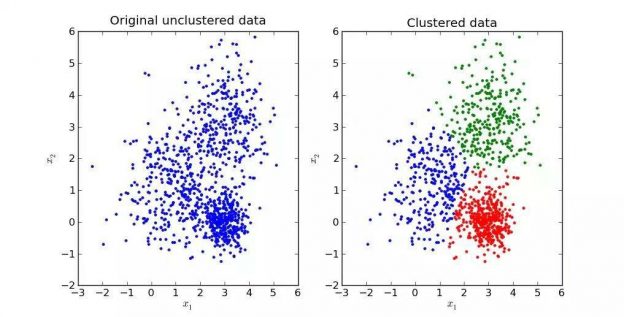
مروری بر الگوریتم K-Means
8 پاسخ