
مقدمه:
این اولین قسمت از مقالههایی هست که قصد دارم راجع به ریاضیات پشت(مربوط) به SVM بنویسم. حرفهای زیادی در مورد پیشزمینه ریاضی که معمولا ضروری هم هست میشه زد. با این وجود من سعی میکنم که آروم پیش برم تا بتونم توضیحهای عمیقتری رو بدم که همه چیز تا حد امکان حتی برای مبتدیها شفاف باشه.
اگر شما تازهکار هستین و مایلید که قبل از ورود به بحثهای ریاضی، بیشتر راجع به SVM بدونید، پیشنهاد میکنم این مقاله را هم مطالعه کنید: آشنایی با ماشین بردار پشتیبان (SVM) – مرور کلی
هدف ماشین ماشین بردار پشتیبان چیست(SVM)؟
هدف ماشین بردار پشتیبان ابن است که بهترین ابر صفحه جداکننده را پیدا کند که مقدار حاشیه بین دادههای آموزشی را به حداکثر برساند.
اولین چیزی که از این تعریف میتوانیم بفهمیم این است که SVM به دادههای آموزشی نیاز دارد. و این به این معنی هست که SVM یک الگوریتم یادگیری نظارتشده است.
مهم است که بدانیم SVM یک الگوریتم طبقهبندی است . این یعنی که از آن برای پیشبینی کردن این که چه چیزی(دادهای) به چه طبقهای(کلاسی) تعلق دارد استفاده میشود.
برای نمونه میتوانیم دادههای آموزشیای را به صورت زیر داشته باشییم:
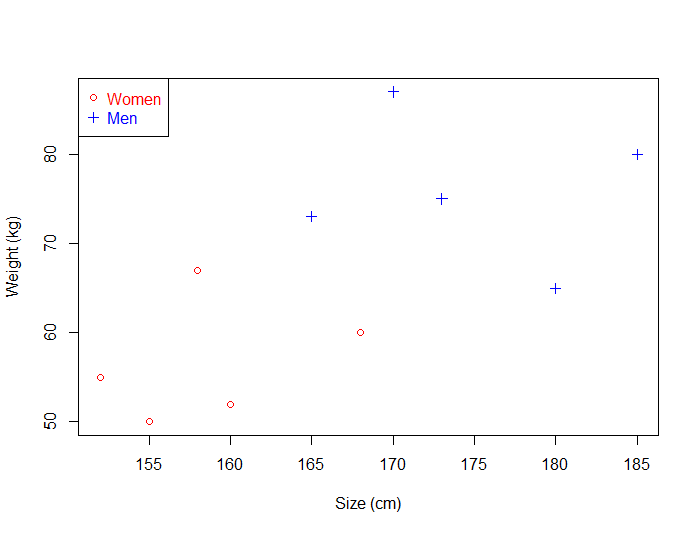
شکل ۱
وزن و قد تعدادی از مردم روی نمودار بالا رسم شده و همچنین راهی وجود دارد که بتوانیم زنها و مردها را از هم تفکیک کنیم.
با داشتن چنین دادههایی، استفاده از یک SVM به ما اجازه میدهد که پاسخ سؤال زیر را بدانیم:
آیا با داشتن یک نقطه مشخص (وزن و قد) میتونیم تشخیص بدیم که این نقطه متعلق به یک زن بوده یا مرد؟
به عنوان مثال: اگر شخصی دارای قد ۱۷۵ سانتیمتر و ۸۰ کیلوگرم وزن باشد، آیا او یک مرد است یا زن؟
ابرصفحه جداکننده چیست؟
با مشاهده نمودار میتوانیم ببینیم که دادهها قابل جداسازی هستند. برای مثال میتوانیم خطی را به گونهای رسم کنیم که نقطههایی که مردها را نمایش میدهند در بالای آن خط و نقطههایی که زنها را نمایش میدهند در پایین آن قرار بگیرند.
چنین خطی ابرصفحه جداکننده نامیده و به صورت زیر نمایش داده میشود:
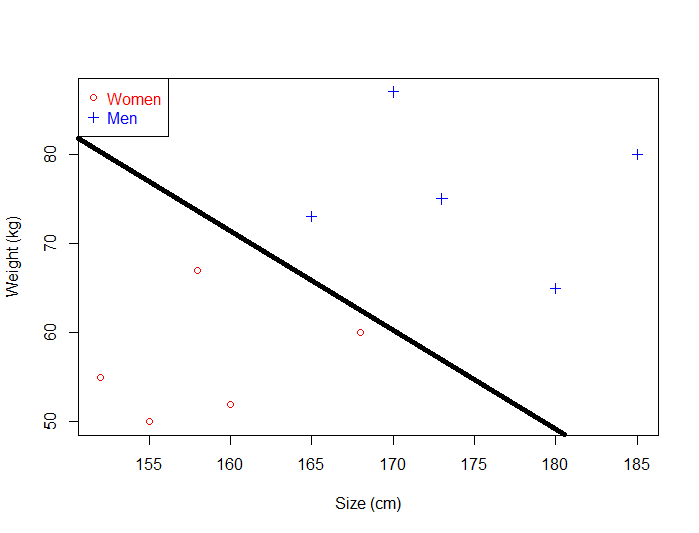
ممکنه این سوال در ذهن شما به وجود بیاد که «این فقط یک خط است، پس چرا آن را ابر صفحه مینامیم؟»
با این که من از یک مثال خیلی ساده و دادههایی که قابل رسم در یک فضای دو بعدی هستند استفاده کردم، ولی ماشین بردار پشتیبان میتواند با هر تعداد بعد دیگر هم کار کند.
یک ابرصفحه تعمیم کلی از یک صفحه است.
- در یک بعد، ابرصفحه نقطه نامیده میشود.
- در دو بعد، ابرصفحه خط نامیده میشود.
- در سه بعد، ابرصفحه صفحه نامیده میشود.
- و برای بعدهای بیشتر، از همان واژه کلی ابرصفحه استفاده میکنیم.

نقطه L به عنوان یک ابرصفحه جداکننده در یک بعد میتواند محسوب شود.
ابرصفحه جداکننده بهینه چیست؟ (بهترین ابرصفحه جداکننده)
این واقعیت که شما میتوانید یک ابرصفحه جداکننده پیدا کنید، به این معنی نیست که آن ابرصفحه بهترین ابرصفحه هست! در مثال زیر چندین ابرصفحه جداکننده وجود دارد. هرکدام از آنها نیز به دلیل این که به خوبی قادر است مجموعه دادهای از مردها و زنها را تفکیک کند، معتبر است.
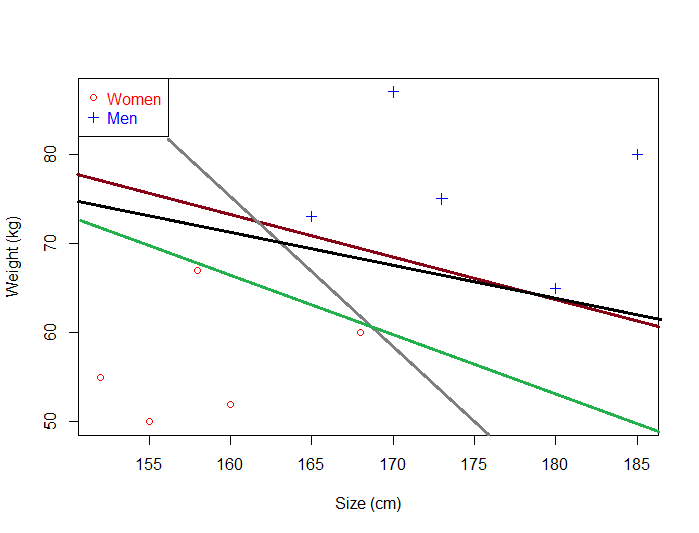
تعداد زیادی ابرصفحه جداکننده میتواند وجود داشته باشد.
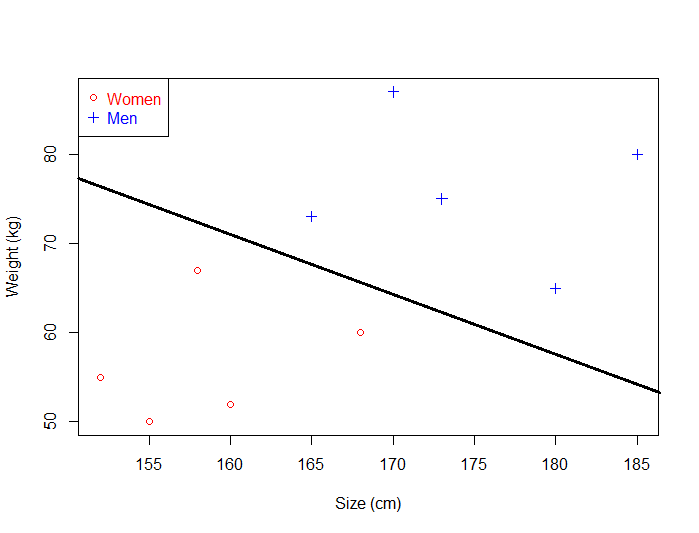
تصور کنید که ابرصفحه سبز رنگ را انتخاب کردهایم و از آن برای طبقهبندی دادههای دنیای واقعی استفاده میکنیم.
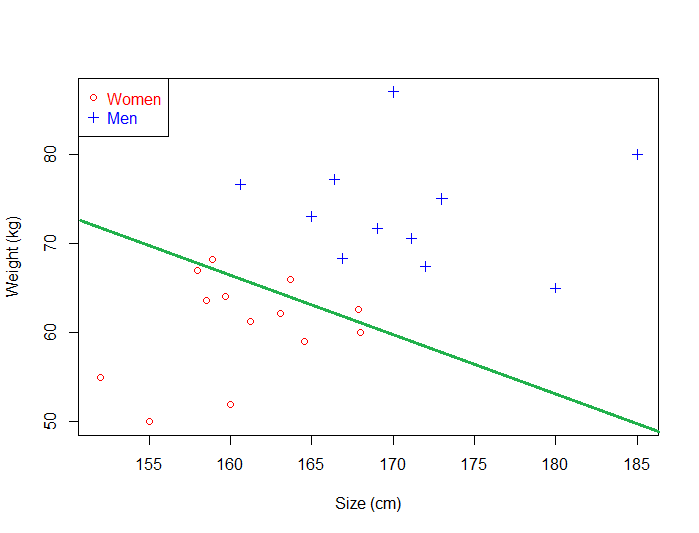
این ابرصفحه نتوانسته است که تعمیم کلی را به خوبی تشخیص دهد
این بار اشتباهاتی رخ داده که در نتیجه آن، ۳ زن به اشتباه در کلاس(طبقه) مردها قرار گرفتهاند. به طور واضح و مستقیم میتوان مشاهده کرد که اگر ابرصفحهای را انتخاب کنیم که به دادههای یک کلاس نزدیک باشد، ممکن است که تعمیم کلی را به خوبی تشخیص ندهیم.
پس سعی بر این است که ابرصفحهای انتخاب شود که تا جایی که ممکن است، از دادههای طبقهبندیها دور باشد.
این مورد بهتر به نظر میرسد. وقتی از آن همراه با دادههای واقعی استفاده کنیم، میتوانیم ببینیم که هنوز طبقهبندی را بدون نقص انجام میدهد.
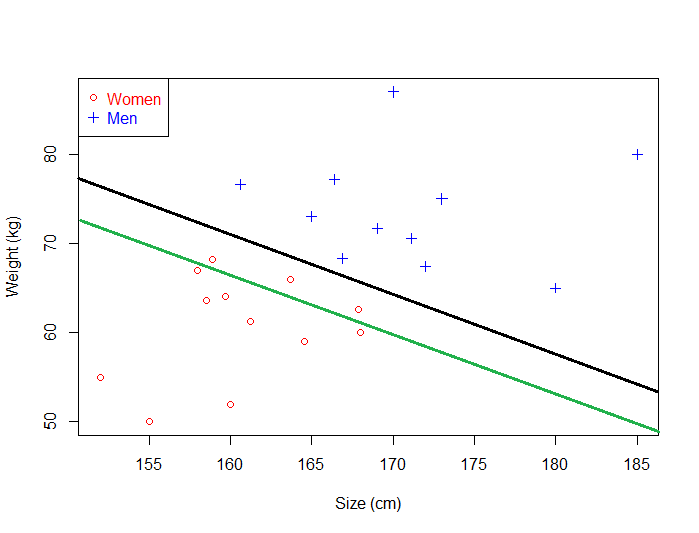
ابرصفحه سیاه رنگ با دقت بیشتری نسبت به ابرصفحه سبز رنگ عمل طبقهبندی را انجام میدهد
به همین دلیل است که هدف SVM پیدا کردن ابرصفحه جداکننده بهینه است.
- به دلیل این که دادههای آموزشی را به خوبی طبقهبندی میکند.
- و به دلیل این که SVM در برابر دادههای دیدهنشده نیز به طور کلی، بهتر عمل میکند.
حاشیه چیست و چگونه به انتخاب ابرصفحه بهینه کمک میکند؟
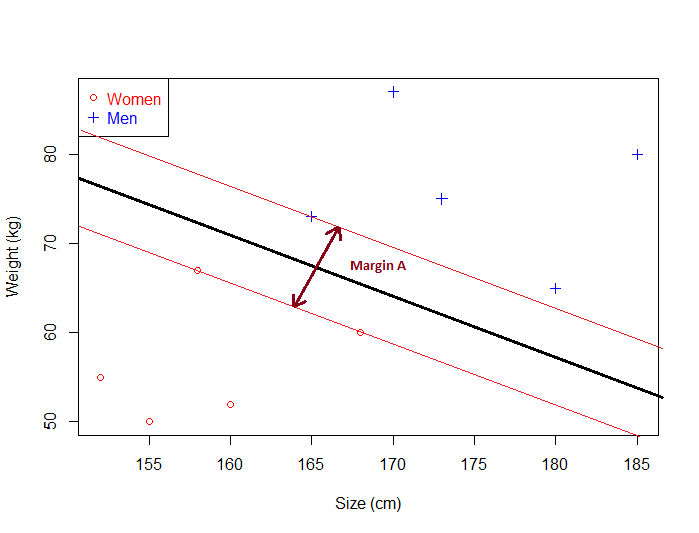
حاشیه ابرصفحه بهبنه برای این مثال
با داشتن یک ابر صفحه مشخص، میتوانیم فاصله بین ابرصفحه و نزدیکترین داده(نقطه) را محاسبه کنیم. وقتی که این مقدار را بدست آوردیم، اگر آن را ۲ برابر کنیم، به ما مقدار چیزی که آن را به عنوان حاشیه(مرز، نوار مرزی) میشناسیم خواهد داد.
اساسا حاشیه، متعلق به هیچ گروه یا طبقهای نیست. بنابراین هیچ دادهای درون آن نمیتواند وجود داشته باشد. (توجه داشته باشید که این موضوع زمانی که دادهها دارای نویز باشند، ممکن است مشکلاتی را ایجاد کند و به این دلیل است که طبقهبندی کننده حاشیه نرم بعدا معرفی خواهد شد.)
برای ابر صفحهای دیگر، حاشیه به صورت زیر خواهد بود:
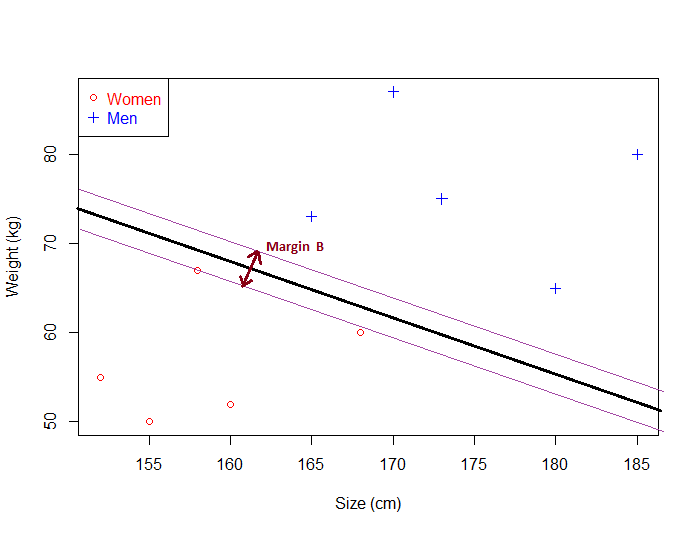
همانطور که مشاهده میکنید، حاشیه B کوچکتر از حاشیه A است.
مشاهدات زیر را نیز میتوانیم داشته باشیم:
- اگر ابرصفحهای زیاد به دادهها نزدیک باشد، حاشیه آن کوچک خواهد بود.
- هرچقدر ابرصفحه از دادهها دورتر باشد، مقدار حاشیه بزرگتر خواهد بود.
و این یعنی ابرصفحه بهینه، بیشترین حاشیه را خواهد داشت.
به همین دلیل است که هدف SVM یافتن ابرصفحه جداکنندهای است که مقدار حاشیه، برای دادههای آموزشی را به حداکثر میرساند.
در این پست سعی کردم که مقدمات ریاضیات پشت SVM را پوشش دهم. تا اینجای کار با فرمولها و رواط ریاضی زیادی سر و کار نداشتیم. ولی در پستهای بعدی با اعداد و ارقام هم سر و کار خواهیم داشت و سعی میکنم که دید ریاضی مورد نیاز را با استفاده هندسه و بردارها پیدا کنیم.
اگر مایلید که بیشتر راجع به ریاضیات مربوط به SVM یاد بگیرید توصیه میکنم که مطلب بعدی را مطالعه کنید:
سلام ممنون از مطلب خوب تون.یه سوال
۱- اگر یه نقطه در ناحیه بالایی به خط ابرصفحه نزدیک تر بود و یک نقطه دیگه در زیر خط، فاصله اش از فاصله ی اون نقطه بالایی از خط بیشتر بود یعنی دو خط موازی بالایی و پایینی که حاشیه رو می سازند فاصله هاشون تا خط اصلی متفاوت بود چطور می شه؟ آیا همچین اتفاقی می افته؟ اگر آره تاثیر در محاسبات خواهد داشت؟
سلام مجدد خدمت شما.
با توجه به پاسخ سؤال قبلیتون همچنین چیزی کاملا رایج و ممکن هست و تغییری در محاسلات به وجود نمیاد. چون بالاخره یکی از این ۲ نقطه نزدیکتره! پس ما فاصله اون رو از ابر صفحه، ۲ برابر میکنیم و حاشیه رو بهدست میاریم.
سلام، اون دو خط موازی بالایی و پایینی مثال شما نمیتونن مربوط به یک حاشیه واحد باشن، چون برای محاسبه حاشیه فاصله خط بالایی از ابرصفحه رو که کمترین هست ۲ برابر میکنیم و بنابر این نقطه پایینی خارج از این حاشیه قرار میگیره.