امروز قصد دارم قبل از وارد شدن به مباحث ریاضی، به صورت کلی راجع به SVMها صحبت کنم و مروری روی آنها داشته باشم.
SVM دقیقا چه چیزی هست؟
SVM یک مدل یادگیری نظارت شده است.

امروز قصد دارم قبل از وارد شدن به مباحث ریاضی، به صورت کلی راجع به SVMها صحبت کنم و مروری روی آنها داشته باشم.
SVM دقیقا چه چیزی هست؟
SVM یک مدل یادگیری نظارت شده است.
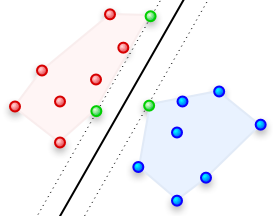
اگه علاقمند هستید که راجع به ماشین بردار پشتیبان (SVM) بیشتر یاد بگیرید و جزییات آن را بدانید، آدرس درستی را انتخاب کردهاید. چون در این پست و پستهای بعدی، من(پیمان برجوییان) قصد دارم راجع به SVM بنویسم. در واقع این پست میشه فهرستی برای بقیه مطالب مربوط به SVM و بالتهایی که اینجا میبینید در آینده به لینکهایی تبدیل خواهند شد و شما را به صفحات مربوط به خودشون راهنمایی خواهند کرد. منبع اصلی این مطلبها کتاب آقای Alexandre Kowalczyk هست و از ایشون بابت اینکه اجازه دادن از مطلبهاشون استفاده و اونا رو به فارسی ترجمه و منتشر کنم، تشکر میکنم. ادامهی خواندن
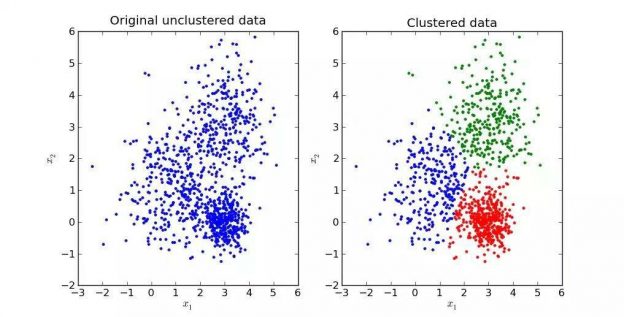
خوشهبندی دادهها رو بر اساس شباهتی که دارن، به طوری که دادههای هر خوشه دارای بیشترین شباهت به هم و کمترین شباهت به دادههای خوشههای دیگه هستن، در یک خوشه قرار میده. الگوریتم K-Means یکی از الگوریتمهای مورد استفاده در داده کاوی و یادگیری ماشینی هست که برای خوشهبندی(Clustering) یا دستهبندی بدون نظارت از اون استفاده میشه. در ادامه نحوه کار این الگوریتم رو با یک مثال و پیادهسازی اون به کمک زبان جاوا توضیح میدم.

تا این جای کار آموختههای من توی چهارچوب دانشگاه و استادهام بود و بیشتر روی سیستمهای توزیع شده و به ویژه روی محاسبات ابری مطالعه و تحقیق کردم.
همیشه دوست داشتم درباره داده کاوی هم مطالعه داشته باشم و حتّی یه روزی دانشمند داده بشم و الآن که دوره کارشناسی ارشدم به پایان رسیده، تا شروع دوره سربازی یه فرصت آزادی دارم که قصد دارم توی اون داده کاوی رو یاد بگیرم.
امّا داده کاوی چیه و به چه درد میخوره؟ دانشمند داده کیه و برای دانشمند داده شدن باید چه چیزهایی رو بدونیم؟