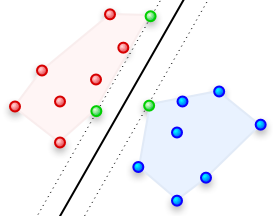
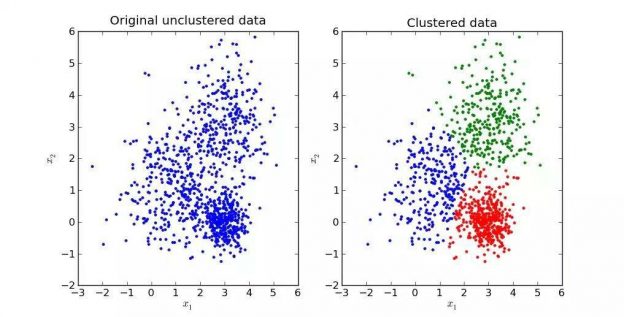
این قسمت دوم از آموزشهای ریاضی مربوط به ماشینهای بردار پشتیبان است. اگر قسمتهای قبلی را هنوز مطالعه نکردهاید، میتوانید آموزش را از قسمت اول با مطالعه مقاله: SVM – درک مفاهیم ریاضی مورد نیاز – قسمت اولشروع کنید.

SVM – درک مفاهیم ریاضی مورد نیاز – قسمت دوم
2 پاسخ