در این پست قصد دارم که مختصری راجع به درخت تصمیم توضیح بدم و در ادامه به زبان پایتون مثالی رو برای اون پیادهسازی کنم.
توجه کنید که امروز قصد ندارم که راجع به جزییات خود الگوریتم صحبت کنم. (شاید در آینده این کارو هم بکنم)
بر اساس ویکیپدیا:
درخت تصمیم یک ابزار برای پشتیبانی از تصمیم است که از درختها برای مدل کردن استفاده میکند. درخت تصمیم به طور معمول در تحقیقها و عملیات مختلف استفاده میشود، به طور خاص در آنالیز تصمیم، برای مشخص کردن استراتژی که با بیشترین احتمال به هدف برسد بکار، میرود. استفاده دیگر درختان تصمیم، توصیف محاسبات احتمال شرطی است.
درختهای تصمیم و الگوریتمهای مربوط به اونا در دادهکاوی و یادگیری ماشینی در دسته الگوریتمهای طبقهبندی(Classification) قرار میگیرن. و این یعنی ما قبل از اجرای اونا به مجموعه دادهای نیاز داریم که از قبل برچسبگذاری شده باشن(Training Data-set). الگوریتمهای ایجاد درخت تصمیم در واقع با توجه به بعدها(ویژگیها) و همچنین برچسب دادههای آموزشی مدلی رو تولید میکنه کنن که با استفاده از اون میتونیم پیشبینی کنیم که دادههای ورودی جدید که در مجموع داده آموزشی وجود نداشتند، دارای چه برچسبی هستند(در چه کلاسی قرار میگیرند یا طبقهبندی میشوند).
همچنین بر اساس ویکیپدیا مزایا و معایب استفاده از درختهای تصمیم را میتوان به صورت زیر برشمرد:
مزایا:
در میان ابزارهای پشتیبانی تصمیم، درخت تصمیم و دیاگرام تصمیم دارای مزایای زیر هستند:
- فهم ساده:هر انسان با اندکی مطالعه و آموزش میتواند، طریقه کار با درخت تصمیم را بیاموزد.
- کارکردن با دادههای بزرگ و پیچیده:درخت تصمیم در عین سادگی میتواند با دادههای پیچیده به راحتی کار کند و از روی آنها مدل تصمیم بسازد.
- استفاده مجدد آسان:در صورتی که درخت تصمیم برای یک مسئله ساخته شد، نمونههای مختلف از آن مسئله را میتوان با آن درخت تصمیم محاسبه کرد.
- قابلیت ترکیب با روشهای دیگر: نتیجه درخت تصمیم را میتوان با تکنیکهای تصمیم سازی دیگر ترکیب کرده و نتایج بهتری بدست آورد.
معایب:
- مشکل استفاده از درختهای تصمیم این است که به صورت نمایی با بزرگ شدن مسئله بزرگ میشوند.
- اکثر درختهای تصمیم تنها از یک ویژگی برای شاخه زدن در گرهها استفاده میکنند در صورتی که ممکن است ویژگیها دارای توزیع توأم باشند.
- ساخت درخت تصمیم در برنامههای داده کاوی حافظه زیادی را مصرف میکند زیرا برای هر گره باید معیار کارایی برای ویژگیهای مختلف را ذخیره کند تا بتواند بهترین ویژگی را انتخاب کند.
پیادهسازی:
کد منبع، مجموعه داده و لیست بستههای استفاده شده(فایل requirements.txt) در این برنامه از طریق مخزن Gitlab آن در دسترس است.
در این مثال به وسیله زبان پایتون ۳.۵ و یک مجموعه داده آموزشی که از قبل برچسبگذاری شدن یک درخت تصمیم ایجاد میکنیم و به کمک این درخت برچسب دو قلم داده ورودی جدید رو پیشبینی میکنیم.
مجموعه داده آموزشی استفاده شده در این مثال ، مربوط به اطلاعات و سوابق استخدام افراد در یک سازمان است که شامل ستونها(ویژگیها، بعدها)ی سوابق تجربی، استخدامهای قبلی، سطح تحصیلات و غیره است که در زیر نمایش داده شده است:
Years Experience,Employed?,Previous employers,Level of Education,Top-tier school,Interned,Hired
که فیلد Hired در واقع همان برچسب داده و به معنی وضعیت استخدام شدن فرد است و دادهها در یک فایل CSV به صورت زیر ذخیره شدهاند:
۱۰,Y,4,BS,N,N,Y
۰,N,0,BS,Y,Y,Y
۷,N,6,BS,N,N,N
۲,Y,1,MS,Y,N,Y
۲۰,N,2,PhD,Y,N,N
۰,N,0,PhD,Y,Y,Y
۵,Y,2,MS,N,Y,Y
۳,N,1,BS,N,Y,Y
۱۵,Y,5,BS,N,N,Y
۰,N,0,BS,N,N,N
۱,N,1,PhD,Y,N,N
۴,Y,1,BS,N,Y,Y
۰,N,0,PhD,Y,N,Y
کد برنامه به صورت زیر هست:
import pandas as pd
from sklearn import tree
from sklearn.externals.six import StringIO
import pydotplus
from sklearn.ensemble import RandomForestClassifier
input_file = "PastHires.csv"
df = pd.read_csv(input_file, header=0)
df.head()
d = {'Y': 1, 'N': 0}
df['Hired'] = df['Hired'].map(d)
df['Employed?'] = df['Employed?'].map(d)
df['Top-tier school'] = df['Top-tier school'].map(d)
df['Interned'] = df['Interned'].map(d)
d = {'BS': 0, 'MS': 1, 'PhD': 2}
df['Level of Education'] = df['Level of Education'].map(d)
df.head()
features = list(df.columns[:6])
features
y = df["Hired"]
X = df[features]
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, y)
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=features)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
# Image(graph.create_png())
graph.write_png('example_graph.png')
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, y)
# Predict employment of an employed 10-year veteran
print(clf.predict([[10, 1, 4, 0, 0, 0]]))
# ...and an unemployed 10-year veteran
print(clf.predict([[10, 0, 4, 0, 0, 0]]))
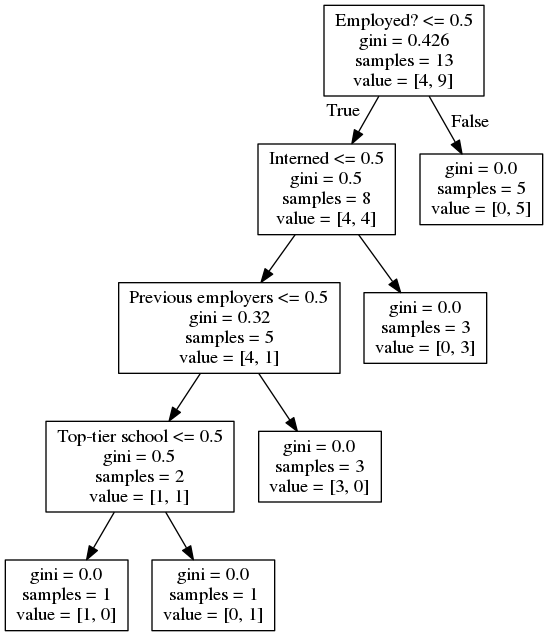
در این برنامه به ترتیب از بالا کتابخانههای مورد نیاز مشخص میشوند، فایل مجموعه داده آموزشی مشخص میشود، دادهها و برچسبهای آنها به فرم استاندارد و قابل فهم برای الگوریتم در میآیند، سپس به وسیله متد DecisionTreeClassifier شیٔ درخت ایجاد میشود و در ادامه دادههای آموزشی به صورت بردار به همراه برچسب آنها به متد fit داده میشوند تا مدل درخت ایجاد شود. پس از ایجاد مدل، تصویر درخت مانند شکل زیر در مسیر برنامه ذخیره میشود.
در ادامه به وسیله n_estimators=10 الگوریتم را ظوری تنظیم میکنیم که قبل از پیشبینی برچسب دادههای ورودی جدید، ۱۰ مدل درخت مختلف را به وسیله انتخاب تصادفی تعدادی از دادههای آموزشی ایجاد کند و در زمان پیشبینی دادههای ورودی جدید، میانگین و یا پاسخ اکثریت آنها را به عنوان برچسب داده ورودی جدید در نظر بگیرد. به این کار، تکنیک جنگل تصادفی(Random Forest) گفته میشود و به دلایل مختلفی از جمله جلوگیری از آموزش بیش از اندازه(Overfitting) و کاهش بار محاسباتی انجام میشود.
حال الگوریتم آماده است تا برچسب دادههای ورودی جدید را پیشبینی کند:
print(clf.predict([[10, 1, 4, 0, 0, 0]]))
print(clf.predict([[10, 0, 4, 0, 0, 0]]))
خروجی دو دستور فوق میتواند ۱ و یا ۰ باشد که به ترتیب به معنی برچسبهای استخدام و عدم استخدام برای این دادهها هستند. (پاسخها در اجراهای مختلف لزوما یکسان نیستند.)
ممکنه براتون این سؤال پیش اومده باشه که در شکل بالا، gini به چه معنی هست، gini پارامتری است که به وسیله اون، در هر انشعاب میزان ناخالصی احتمالی نمایش داده میشه.
موفق باشید.