این قسمت چهارم از آموزش مفاهیم ریاضی پشت ماشینهای بردار پشتیبان است. در این پست نحوه حل کردن مسأله کمینهسازی بدون قید را یاد میگیریم.
اگر قسمتهای قبلی را هنوز مطالعه نکردهاید، میتوانید آموزش را از قسمت اول با مطالعه مقاله:SVM – درک مفاهیم ریاضی مورد نیاز – قسمت اول شروع کنید.
درباره این قسمت
نوشتن این قسمت به دلیل گسترده بودن موضوع و دانش اولیه زیادی که نیاز دارد، زمان زیادی را از من گرفت. این که چه مطلبهایی را باید توضیح دهم و از روی چه مطلبهایی باید رد شوم هم تصمیم سختی بود. پس از مدتی با یک پست طولانی مواجه شدم که مطالعه آن مشکل میشد. برای همین تصمیم گرفتم که این پست را به چند قسمت تقسیم کنم. پس به قسمتهای ۴، ۵ و ۶ خوشآمدید و خوش خواهید آمد! 🙂
در این پست سعی شده که مطلبها تا حد ممکن برای همه ساده باشند، ولی با این وجود من نمیتوانم که همه چیز را کامل توضیح دهم. برای همین من فرض میکنم که شما از قبل با مشتقها و مشتقهای جزیی آشنایی دارید. همچنین انتظار میرود که شما ماتریس و ترانهاده ماتریس را بشناسید و نحوه محاسبه دترمینان ماتریس را نیز بدانید.
در طول چند ماه گذشته، من نظرها و تشویقهای زیادی را دریافت کردم. خیلیها هم زمان انتشار این پست و بقیه قسمتها را پیگیری کردهاند. همینجا از همه شما تشکر میکنم و امیدوارم که از آموزشها لذت ببرید.
جایی که مسأله را رها کردیم
در قسمت سوم, متوجه شدیم که برای به حداکثر رساندن مقدار حاشیه، باید اندازه (نرم)  را به حداقل برسانیم.
را به حداقل برسانیم.
این یعنی ما باید مسأله بهینهسازی زیر را حل کنیم:
کمینه کردن با توجه به (w, b)

با توجه به 
(برای هر  )
)
اولین نکتهای که درباره این مسأله بهینهسازی باید به آن توجه کنیم این است که این مسأله دارای قیدهایی هست. این قیدها در خطی که با عبارت «با توجه به» شروع میشود تعریف شدهاند. ممکن است که شما فکر کنید، فقط یک قید داریم، ولی درواقع  قید داریم. (به دلیل وجود عبارت «به ازای هر» در خط آخر)
قید داریم. (به دلیل وجود عبارت «به ازای هر» در خط آخر)
“خیلی خب، چطور باید این مسأله را حل کنیم؟ (به احتمال زیاد زمان زیادی را منتظر پاسخ این سؤال بودهاید!!!)”

قبل از دست و پنجه نرم کردن با چنین مسأله پیچیدهای، اجازه دهید که با یک مسأله سادهتر شروع کنیم. اول باید ببینیم که یک مسأله بهینهسازی بدون قید را باید حل کرد، یا بهطور دقیقتر کمینهسازی بدون قید را فرا خواهیم گرفت. این همان مسأله پیدا کردن ورودیای است که باعث میشود تابع، کمترین مقدار خودش را تولید کند و یا برگرداند. (توجه کنید که در مورد SVM، مایل هستیم تابعی که نرم (اندازه) را محاسبه میکند، کمینه کنیم. میتوانیم این تابع را  بنامیم و آن را به صورت
بنامیم و آن را به صورت  بنویسیم.)
بنویسیم.)
حداقلسازی بدون قید
اجازه دهید نقطه  را در نظر بگیریم. (شما باید این را “x ستاره” بخوانید، ما فقط یک ستاره به آن اضافه کردیم که بدانید درباره یک متغیر خاص صحبت میکنیم نه درباره هر x)
را در نظر بگیریم. (شما باید این را “x ستاره” بخوانید، ما فقط یک ستاره به آن اضافه کردیم که بدانید درباره یک متغیر خاص صحبت میکنیم نه درباره هر x)
چطور بدانیم که یک مینیمم محلی تابع است؟ خب این تقریبا ساده است. ما فقط نیاز داریم که قضیه زیر را اعمال کنیم:
قضیه:
 تابعی است پیوسته و مشتقپذیر که مشتق دوم آن در موجود است.
تابعی است پیوسته و مشتقپذیر که مشتق دوم آن در موجود است.
اگر در رابطه  صدق کند و
صدق کند و  همیشه مثبت باشد، در این صورت یک مینیمم محلی است.
همیشه مثبت باشد، در این صورت یک مینیمم محلی است.
حقیقت تلخی که در این قضیه وجود دارد این است که با وجود مختصر بودن، فهمیدن آن بدون داشتن مقداری اطلاعات و دانش قبلی، تقریبا غیرممکن است. چیست؟ چیست؟ منظور از همیشه مثبت چیست؟
در بعضی از موارد اطلاعات بیشتری به ما داده خواهد شد و به کمک آنها، قضیه قبل میتواند به صورت زیر نوشته شود:
قضیه (با جزییات بیشتر):
اگر صدق کند:
۱. یک گرادیان صفر در دارد:
و
۲. Hessian در همیشه مثبت است:

جایی که:
![\[ \nabla ^2 f(x) = \begin{pmatrix} \frac{\delta ^2 f}{\delta x_1 ^2} & \cdots & \frac{\delta ^2 f}{\delta x_1 \delta x_n} \\ \vdots & \ddots & \vdots \\ \frac{\delta ^2 f}{\delta x_n \delta x_1} & \cdots & \frac{\delta ^2 f}{\delta x_n ^2} \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-462bea05b88c0d5dfcb62f07a73b27fa_l3.png "Rendered by QuickLaTeX.com")
در این صورت یک مینیمم محلی است.
همه اینها به چه معنی هستند؟
اجازه دهید که این تعریف را قدم به قدم ارزیابی کنیم.
قدم اول:
که تابعی است پیوسته و مشتقپذیر که مشتق دوم آن در موجود است را در نظر بگیرید.
اول تابعی که آن را مینامیم را معرفی میکنیم. این تابع مقدارهایش را از مجموعه  (امگا) میگیرد . یک مقدار حقیقی را برمیگرداند. اولین سختی که در اینجا وجود دارد این هست که ما نمیتوانیم مقدار را مشخص کنیم ولی مقدار آن را در خط بعدی حدس بزنیم. این تابع باید پیوسته باشد و مشتق دوم آن نیز موجود باشد و در غیر این صورت ادامه تعریف نادرست خواهد بود.
(امگا) میگیرد . یک مقدار حقیقی را برمیگرداند. اولین سختی که در اینجا وجود دارد این هست که ما نمیتوانیم مقدار را مشخص کنیم ولی مقدار آن را در خط بعدی حدس بزنیم. این تابع باید پیوسته باشد و مشتق دوم آن نیز موجود باشد و در غیر این صورت ادامه تعریف نادرست خواهد بود.
قدم دوم:
یک مینیمم محلی است، اگر و فقط اگر:
میخواهیم مقداری را پیدا کنیم که وقتی آن را به میدهیم، کمترین مقدار خود را تولید کند. ما این مقدار را به طور ساده مینامیم.
از این علامت دو چیز را میتوانیم نتیجه بگیریم:
- به صورت ضخیم (Bold) نوشته شده است. پس این یک بردار است. این یعنی یک تابع چند متغیره است.
- در نتیجه مجموعه که پیشتر آن را دیدهایم، مجموعهای است که ما مقدارهایی از آن را به میدهیم. این یعنی مجموعه مجموعهای از بردارها است و
 (“x ستاره امگا (Omega) تعلق دارد”).
(“x ستاره امگا (Omega) تعلق دارد”).
قدم سوم:
یک گرادیان صفر در دارد.
اگر بخواهیم یک مینیمم محلی  باشد. این اولین شرطی است که باید در نظر بگیریم. ما باید بررسی کنیم که گرادیان تابع در برابر با صفر باشد. گرادیان چیست؟ این اسم را فقط به عنوان یک مشتق در نظر بگیرید.
باشد. این اولین شرطی است که باید در نظر بگیریم. ما باید بررسی کنیم که گرادیان تابع در برابر با صفر باشد. گرادیان چیست؟ این اسم را فقط به عنوان یک مشتق در نظر بگیرید.
تعریف: “گرادیان یک فرم کلیتر از مفهوم مشتق یک تابع در یک بعد از چند بعد است.” (ویکیپدیا)
این تعریف به ما قسمتی از اطلاعات مورد نیاز را میدهد. گرادیان در حقیقت همان مشتق است. اما برای تابعهایی مثل ، بردارها را به عنوان ورودی میگیرد. برای همین است که ما نیاز داریم تا در درجه اول تابع مشتقپذیر باشد. اگر اینطور نباشد نمیتوانیم گرادیان را محاسبه کنیم و ادامه دهیم.
در محاسبات، زمانی که ما میخواهیم یک تابع را بررسی کنیم، معمولا علامت مشتق آن را بررسی میکنیم. این به ما اجازه میدهد که صعودی یا نزولی بودن و همچنین مینیمم و ماکزیمم تابع را مشخص کنیم. با برابر کردن مشتق با صفر میتوانیم نقطههای بحرانی تابع که در آنها به حداکثر و حداقل خود میرسد را پیدا کنیم. (توجه: برای تابعهایی که متغیرهای بیشتری دارند، باید مشتقهای جزیی را در این نقطه برابر صفر قرار دهیم.)
گرادیان یک تابع با علامت  (nabla) نمایش داده میشود.
(nabla) نمایش داده میشود.
عبارت
فقط یک بیان دیگر از “ در گرادیان صفر دارد” به کمک علامتهای ریاضی است.
برای بردار  ،
،  یعنی:
یعنی:



قدم چهارم:
ماتریس Hessian تابع در همیشه مثبت است.
این جایی هست که بیشتر مردم گیج میشوند. این جمله به تنهایی نیاز به مقدار زیادی پیشزمینه دارد. شما باید موارد زیر را بدانید:
- ماتریس Hessian یک ماتریس از مشتقهای مرتبه دوم است.
- چطور میتوان همیشه مثبت بودن یک ماتریس را مشخص کرد؟
ماتریس Hessian
ماتریس Hessian یک ماتریس است و فقط یک اسم به آن نسبت دادهایم. می توانستیم آن را H بنامیم ولی در عوض برای صراحت بیشتر، آن را  مینامیم. ما همان سمبل که برای گرادیان استفاده کردیم را نگه داشتیم و به آن یک
مینامیم. ما همان سمبل که برای گرادیان استفاده کردیم را نگه داشتیم و به آن یک  اضافه کردهایم که نشان دهیم این بار درباره مشتقهای جزیی مرتبه دوم صحبت میکنیم. سپس به تابعی که این مشتقها را محاسبه میکند نام را اختصاص میدهیم. با نوشتن میدانیم که یک بردار
اضافه کردهایم که نشان دهیم این بار درباره مشتقهای جزیی مرتبه دوم صحبت میکنیم. سپس به تابعی که این مشتقها را محاسبه میکند نام را اختصاص میدهیم. با نوشتن میدانیم که یک بردار  را به عنوان ورودی میگیرد و ماتریس Hessian برای داده شده محاسبه میشود.
را به عنوان ورودی میگیرد و ماتریس Hessian برای داده شده محاسبه میشود.
جمعبندی: ما باید ماتریسی به نام Hessian را برای محاسبه کنیم.
پس ما با داشتن تابع و مقدار همه سلولهای ماتریس را به وسیله فرمول زیر محاسبه میکنیم:
در نهایت ما ماتریس Hessian را خواهیم داشت که حاوی همه عددهایی است که محاسبه کردهایم.
اجازه دهید نگاهی به تعریف بیاندازیم تا مطمئن شویم که آن را خوب متوجه شدهایم.
تعریف: در ریاضی ماتریس Hessian یا Hessian یک ماتریس مربعی از مشتقهای جزیی مرتبه دوم یک تابع با مقدارهای اسکالر است. این ماتریس انحنای محلی تابعی از چند متغیر را توصیف می کند. (ویکیپدیا)
(توجه: یک تابع با مقدار اسکالر، تابعی است که یک یا چند مقدار را میگیرد ولی فقط یک مقدار را برمیگرداند. در مورد ما یک تابع اسکالر است.)
همیشه مثبت
حال که ماتریس Hessian را داریم، میخواهیم بدانیم که آیا در همیشه مثبت است؟
تعریف: یک ماتریس متقارن  همیشه مثبت است اگر به ازای همه
همیشه مثبت است اگر به ازای همه 
 باشد. (منبع)
باشد. (منبع)
این بار قبل از هرچیز، یکبار دیگر به تعریف داده شده توجه میکنیم. خواندن آن ممکن است به دلیل استفاده از علامتهای ریاضی، کمی مشکل باشد. اگر ما جای را با عوض کنیم، دقیقا به همان فرمول قسمت دوم میرسیم. از قضیه با جزییات بیشتر میدانیم:
مشکل این تعریف این است که درباره ماتریس متقارن صحبت میکند. یک ماتریس متقارن یک ماتریس مربعی است که با ترانهاده خود برابر باشد.
ماتریس Hessian مربعی است، ولی آیا متقارن هم هست؟
از شانس خوب ما بله!
“اگر مشتقهای دوم همگی در همسایگی  پیوسته باشند، در نتیجه Hessian یک ماتریس متقارن در محدوده بازه دارد.” (ویکیپدیا)
پیوسته باشند، در نتیجه Hessian یک ماتریس متقارن در محدوده بازه دارد.” (ویکیپدیا)
اما حتی با تعریف، ما هنوز نمیدانیم که چطور همیشه مثبت بودن Hessian را بررسی کنیم. این به خاطر فرمول  برای همه
برای همه  در
در  است.
است.
ما نمیتوانیم که این فرمول را برای همه مقدارهای در امتحان کنیم!
برای همین از قضیه زیر استفاده میکنیم:
قضیه:
جملههای زیر با هم برابرند:
- ماتریس متقارن همیشه مثبت است.
- همه eigenvalueهای مثبت هستند.
- همه leading principal minorهای مثبت هستند.
- ماتریس nonsingular مربعی
 به قسمی که
به قسمی که  وجود دارد. (منبع)
وجود دارد. (منبع)
پس ما سه راه داریم که همیشه مثبت بودن یک ماتریس را بررسی کنیم:
- به وسیله محاسبه eigenvalueهای آن و بررسی این که آنها مثبت هستند.
- به وسیله محاسبه leading principal minorهای آن و بررسی این که آنها مثبت هستند.
- به وسیله پیدا کردن یک ماتریس مربعی nonsingular به قسمی که .
اجازه دهید از روش دوم استفاده کنیم و آن را با جزییات بیشتر بررسی کنیم.
محاسبه leading principal minors (کهاد)
Minors
برای محاسبه  سطر
سطر  و ستون
و ستون  را حذف میکنیم و دترمینان باقیمانده ماتریس را محاسبه میکنیم.
را حذف میکنیم و دترمینان باقیمانده ماتریس را محاسبه میکنیم.
مثال:
ماتریس ۳*۳ زیر را در نظر بگیرید:
![\[ \begin{pmatrix} a & b & c \\ d & e & f \\ g & h & i \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-46415c532136782daa5533b340975137_l3.png "Rendered by QuickLaTeX.com")
برای محاسبه Minor  12 این ماتریس، سطر شماره ۱ و ستون شماره ۲ را حذف میکنیم. بنابراین خواهیم داشت:
12 این ماتریس، سطر شماره ۱ و ستون شماره ۲ را حذف میکنیم. بنابراین خواهیم داشت:
![\[ \begin{pmatrix} \Box & \Box & \Box \\ d & \Box & f \\ g & \Box & i \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-805c54314619369b08470a218fefd524_l3.png "Rendered by QuickLaTeX.com")
سپس دترمینان ماتریس زیر را محاسبه میکنیم:
![\[ \begin{pmatrix} d & f \\ g & i \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-7d6c70e762f0f6bad386bb3d74438e92_l3.png "Rendered by QuickLaTeX.com")
که برابر است با: 
Principal minors
یک minor زمانی که  باشد، principal minor نامیده میشود.
باشد، principal minor نامیده میشود.
برای ماتریس ۳*۳ ما، principal minorها به صورت زیر هستند:



هنوز تمام نشده! در واقع minorها همچنین دارای چیزی که ما آن را مرتبه مینامیم هستند.
تعریف:
یک minor از مرتبه  اگر با حذف کردن
اگر با حذف کردن  سطر و ستون با شمارههای یکسان به دست بیاید، principal است. (منبع)
سطر و ستون با شمارههای یکسان به دست بیاید، principal است. (منبع)
در مثال قبل، ماتریسی که استفاده شد ۳*۳ بود. پس  است و ما ۱ سطر را حذف کردیم، در نتیجه ما minorهای مرتبه دوم را محاسبه کردیم.
است و ما ۱ سطر را حذف کردیم، در نتیجه ما minorهای مرتبه دوم را محاسبه کردیم.

 principal minor مرتبه وجود دارد و ما هر یک از آنها را با
principal minor مرتبه وجود دارد و ما هر یک از آنها را با  نمایش میدهیم.
نمایش میدهیم.
برای جمعبندی:
 : وجود ندارد، زیرا اگر ما سه سطر و سه ستون را حذف کنیم، در واقع کل ماتریس را حذف کردهایم.
: وجود ندارد، زیرا اگر ما سه سطر و سه ستون را حذف کنیم، در واقع کل ماتریس را حذف کردهایم.
 :
:  سطر و ۲ ستون با شماره یکسان را حذف میکنیم.
سطر و ۲ ستون با شماره یکسان را حذف میکنیم.
پس ما سطرهای ۱ و ۲ و ستونهای ۱ و ۲ را حذف میکنیم.
![\[ \begin{pmatrix} \Box & \Box & \Box \\ \Box & \Box & \Box \\ \Box & \Box & i \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-9b5f794aec7ffc0ae0eaa4d61e69bf33_l3.png "Rendered by QuickLaTeX.com")
این یعنی یک principal minor از مرتبه ۱، است. اجازه دهید که بقیه را نیز پیدا کنیم:
سطرهای ۲ و ۳ و ستونهای ۲ و ۳ را حذف میکنیم و  به دست میآید.
به دست میآید.
سطرهای ۱ و ۳ و ستونهای ۱ و ۳ را حذف میکنیم و  به دست میآید.
به دست میآید.
 : همان چیزی است که قبلا آن را دیدهایم:
: همان چیزی است که قبلا آن را دیدهایم:
 : چیزی را حذف نمیکنیم. پس این همان دترمینان ماتریس است:
: چیزی را حذف نمیکنیم. پس این همان دترمینان ماتریس است: 
Leading principal minor (کهاد)
تعریف:
کهاد از مرتبه همان minor از مرتبه است که از حذف کردن سطر و ستون آخر به دست آمده است.
در نتیجه این موضوع به دست آوردن کهاد را سادهتر خواهد کرد. اگر ما  را برای کهاد از مرتبه بنویسیم، متوجه خواهیم شد که:
را برای کهاد از مرتبه بنویسیم، متوجه خواهیم شد که:
 (دو سط و ستون آخر را حذف کردهایم)
(دو سط و ستون آخر را حذف کردهایم)
 (سطر آخر و ستون آخر را حذف کردهایم)
(سطر آخر و ستون آخر را حذف کردهایم)

حال که همه کهادهای ماتریس را محاسبه کردهایم، میتوانیم آنها را به ازای ماتریس Hessian محاسبه کنیم و اگر همه آنها مثبت باشند، متوجه خواهیم شد که ماتریس همیشه مثبت است.
حال که ما هر آنچه که نیاز داریم را میدانیم را کاملا ارزیابی کردیم و شما قادر هستید که راه حل یک مسأله کمینهسازی بدون قید را درک کنید، اجازه دهید که با یک مثال بررسی کنیم که تا الآن این همه چیز را به خوبی متوجه شدهاید.
مثال:
در این مثال سعی خواهیم کردکه مقدار حداقل تابع  که با نام تابع موزی روزنبروک (Rosenbrock’s banana function) شناخته میشود را پیدا کنیم.
که با نام تابع موزی روزنبروک (Rosenbrock’s banana function) شناخته میشود را پیدا کنیم.
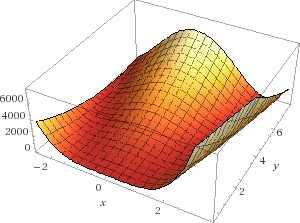
تابع روزنبروک به ازای  و
و 
اول، به دنبال نقطههایی که  را برابر با صفر میکنند خواهیم گشت.
را برابر با صفر میکنند خواهیم گشت.
![\[ \Delta f(x,y) = \begin{pmatrix} \frac{\delta f}{\delta x} \\ \frac{\delta f}{\delta y} \\ \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-3f262f48320515f716000e0f0b973864_l3.png "Rendered by QuickLaTeX.com")
بنابراین مشتقهای جزیی را محاسبه میکنیم:


(راهنمایی: اگر میخواهید از درستی محاسبات خود مطمئن شوید، میتوانید از ابزار Wolfram alpha استفاده کنید.)
هدف ما پیدا کردن حالتی است که پاسخ هر دو معادله، برابر با صفر میشود، پس ما نیاز داریم تا دستگاه معادلات زیر را حل کنیم:


اگر معادله را باز کنیم، خواهیم داشت:


معادله (۲) را در  ضرب میکنیم:
ضرب میکنیم:

حال معادله (۳) و (۵) را باهم جمع میکنیم:

که به صورت زیر ساده میشود:


را در معادله شماره (۴) جایگذاری میکنیم




به نظر میرسد که ما نقطه  که در
که در  صدق میکند را پیدا کردهایم.
صدق میکند را پیدا کردهایم.
ماتریس Hessian برابر است با:
![\[ \nabla ^2 f(x, y) = \begin{pmatrix} \frac{\delta ^2 f}{\delta x^2} & \frac{\delta ^2 f}{\delta xy} \\ \frac{\delta ^2 f}{\delta yx} & \frac{\delta ^2 f}{\delta y^2} \end{pmatrix} \]](https://www.outlier.ir/wp-content/ql-cache/quicklatex.com-cfdb8b0e3602a5468e12060e55558722_l3.png "Rendered by QuickLaTeX.com")




حال اجازه دهید Hessian را برای محاسبه کنیم

ماتریس متقارن است. میتوانیم کهادهای آن را بررسی کنیم:
Minorهای مرتبه اول:
اگر ما سطر و ستون آخر را حذف کنیم،  برابر ۳۲۰۲ خواهد بود.
برابر ۳۲۰۲ خواهد بود.
Minorهای مرتبه دوم:
این همان دترمینان ماتریس Hessian است:

همه کهادهای Hessian مثبت هستند. این یعنی Hessian همیشه مثبت است.
دو شرطی که لازم داشتیم، برآورده شده و میتوانیم نتیجه بگیریم که نقطه  یک مینیمم محلی است.
یک مینیمم محلی است.
مینیمم محلی؟
به یک نقطه، کمینه محلی گفته میشود زمانی که کوچکترین مقدار در یک بازه باشد. به صورت رسمیتر:
با داشتن تابع که در دامنه  تعریف شده باشد، نقطه کمینه محلی است اگر یک
تعریف شده باشد، نقطه کمینه محلی است اگر یک  وجود داشته باشد که برای هر در بازه در فاصله
وجود داشته باشد که برای هر در بازه در فاصله  از ،
از ،  باشد. این موضوع در شکل زیر نشان داده شده است.
باشد. این موضوع در شکل زیر نشان داده شده است.
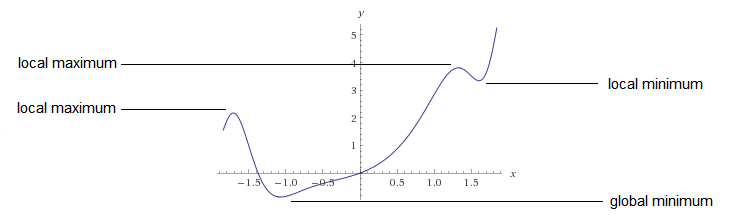
همچنین یک مینیمم سراسری، در تمام بازه دامنه تابع صحیح است.
با داشتن تابع که در دامنه تعریف شده است، نقظه کمینه سراسری است اگر:
برای همه xهای موجود در
همه سختی کار ما، فقط پیدا کردن مینیمم محلی بود، ولی در زندگی واقعی، ما معمولا میخواهیم مینیمم سراسری را پیدا کنیم…
مینیمم سراسری را چطور پیدا کنیم؟
یک راه ساده برای پیدا کررن مینیمم سراسری وجود دارد:
- همه مینیممهای محلی را پیدا کنید
- کوچکترین آنها را بیابید و این همان مینیمم سراسری است.
یک رویکرد دیگر مطالعه تابعی است که قصد کمینه کردن آن را داریم. اگر این تابع محدب باشد، مطمئن هستیم که مینیمم محلی آن، همان مینیمم سراسری است.
نتیجهگیری
دیدیم که پیدا کردن مینیمم یک تابع، خیلی هم کار سادهای نیست و تازه این به معنی پیدا کردن مینیمم سراسری هم نبود. با این حال، کار کردن با بعضی از تابعها که محدب نامیده میشوند، سادهتر است. تابع محدب چیست؟ قسمت پنجم این آموزش را مطالعه فرمایید تا جواب این سؤال را پیدا کنید! ممنون که تا اینجا با من بودید.