سلام. در این پست راجع به بایاس، واریانس و مصالحه(سبک سنگین کردن یا trade off) بین آنها میپردازم.
نگاه کردن از دریچه بایاس، واریانس و مصالحه میان آنها، به درک بهتر الگوریتمهای یادگیری ماشین کمک میکند.
بایاسها فرضهایی که توسط مدل برای آسانتر شدن یادگیری تابع هدف ساخته میشوند را سادهتر میکنند.
در کل، الگوریتمهای پارامتری، بایاس بیشتری دارند که باعث میشود در یادگیری سریعتر باشند و راحتتر فهمیده شوند ولی انعطافپذیری آنها به طور کلی کمتر شود. به عبارت دیگر کارایی آنها در پیشبینی مسائل پیچشده کمتر است که باعث میشود در سادهسازی فرضهای بایاس الگوریتمها شکست بخورند.
درختهای تصمیم یک نمونه از الگوریتم با بایاس کم هستند درحالی که رگرسیون خطی، یک نمونه از الگوریتم با بایاس بالا است.
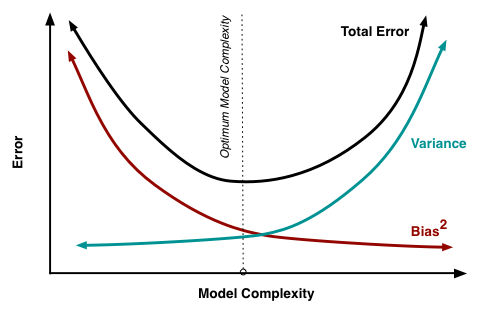
واریانس مقدار تغییراتی است که استفاده از دادههای آموزشی متفاوت، در تخمین تابع هدف ایجاد میکند. تابع هدف با توجه به داده آموزشی با استفاده از یک الگوریتم یادگیری ماشین تخمین زده میشود. پس باید انتظار مقداری واریانس(مقدار غیر صفر) را از الگوریتم داشته باشیم.
الگوریتم k-همسایه نزدیکتر(k-Nearest Neighbors)، نمونهای از یک الگوریتم با واریانس بالا است درحالی که تحلیل تمایز خطی(Linear Discriminant Analysis)، نمونهای از یک الگوریتم با واریانس پایین است.
هدف هر الگوریتم یادگیری ماشین پیشبینی کننده، رسیدن به بایاس و واریانس پایین است. به عبارت دیگر الگوریتم باید به کارایی پیشبینی خوبی برسد. در پارامتری کردن(مشخص کردن پارامترهای) الگوریتمهای یادگیری ماشین، معمولا جدال بر سر برقراری توازن میان بایاس و واریانس است.
- افزایش بایاس، واریانس را کاهش خواهد داد.
- افزایش واریانس، بایاس را کاهش خواهد داد.
آگاهی از این موارد به درک بهتر رگرسیون خطی کمک خواهد کرد.
شاد باشید.