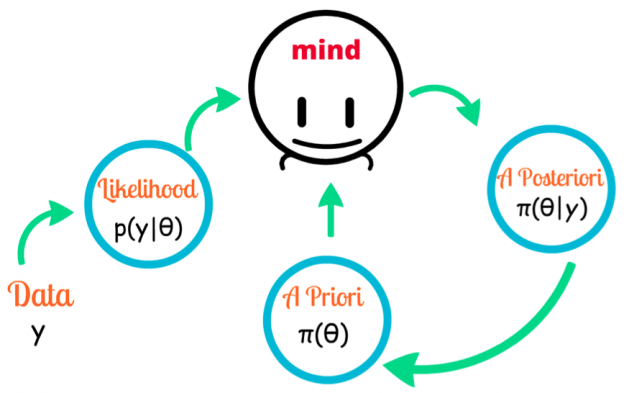
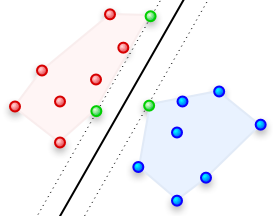
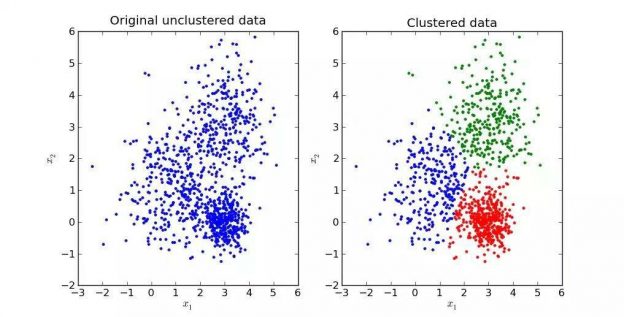
طبقهبندی کننده بیز ساده (Naive Bayes) طبقهبندی کننده ساده و شناخته شدهای است که در مواقعی که تعداد مشاهدات کمی در دسترس باشد نیز عملکرد خوبی دارد. در این آموزش یک طبقهبندی کننده بیز ساده گاوسی (Gaussian Naive Bayes) را از پایه ایجاد خواهیم کرد و با استفاده از آن، کلاس (طبقهبندی یا برچسب) نقاط داده که از قبل دیده نشدهاند را پیشبینی میکنیم.

طبقهبندی کننده بیز ساده (Naive Bayes)
پاسخ دهید